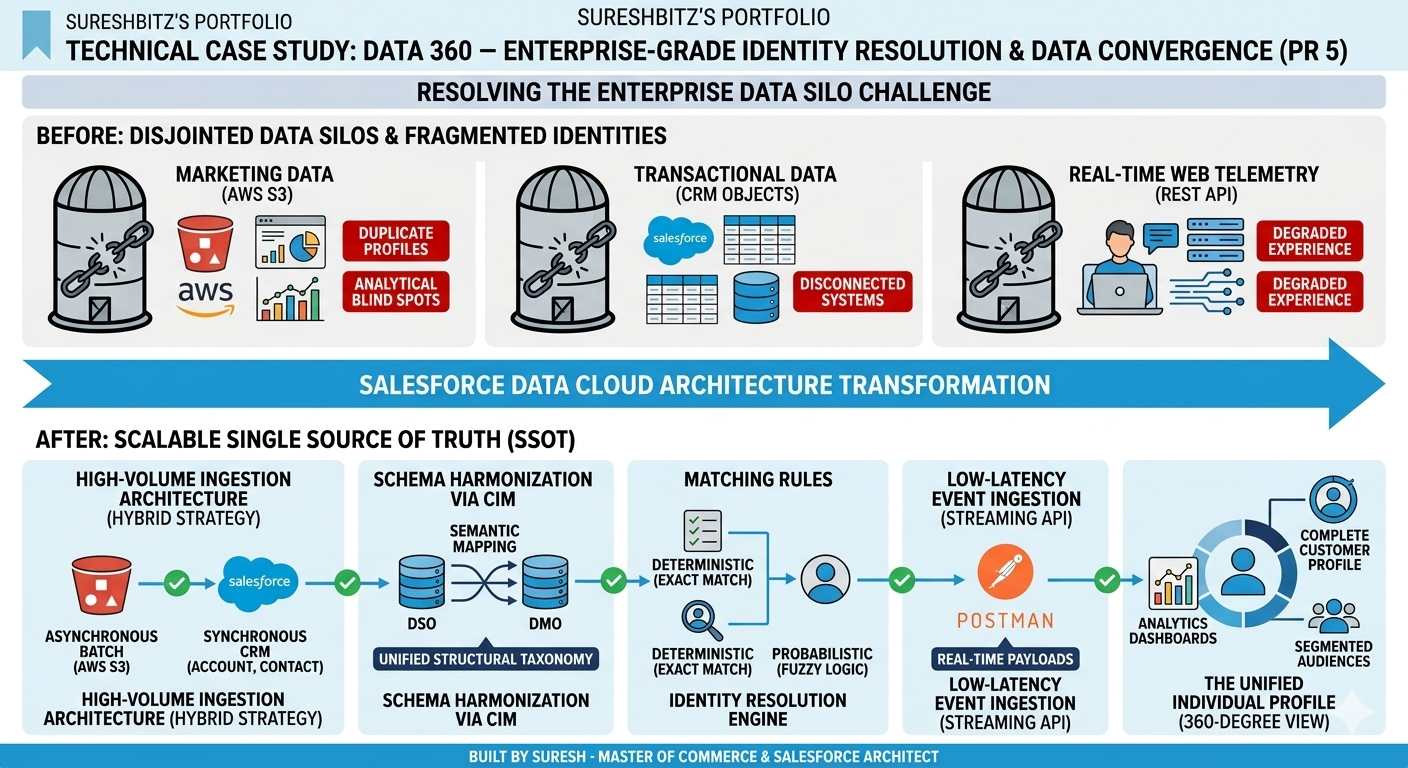
Introduction: The Enterprise Data Silo Challenge
Modern enterprises face a critical bottleneck: disjointed data silos. Customer interactions are routinely fragmented across disconnected systems—marketing lists, transactional databases, and real-time web telemetry. This lack of architectural cohesion results in duplicate identities, analytical blind spots, and degraded customer experiences.
In this project, I architected and implemented a comprehensive Salesforce Data Cloud solution to resolve this challenge. By building an automated data pipeline, I established a scalable Single Source of Truth (SSOT) that ingests, harmonizes, and unifies disparate data streams into a single, comprehensive 360-degree customer profile.
Technical Architecture & Implementation Phases
Phase 1: High-Volume Ingestion Architecture
To build a true data foundation, the platform required a hybrid ingestion strategy capable of handling both massive historical datasets and real-time operational data.
- Asynchronous Batch Ingestion (AWS S3): Engineered secure data streams from Amazon S3 buckets to ingest large-scale historical purchase logs and contact registries. Implemented automated, scheduled refresh cycles to incrementally poll the cloud storage buckets for optimized data loading.
- Synchronous CRM Ingestion: Utilized native high-performance connectors to establish direct data streams from standard Salesforce CRM objects (
Account,Contact), ensuring operational pipeline alignment.
Phase 2: Schema Harmonization via the Cloud Information Model (CIM)
Raw incoming data frequently suffers from schema friction (e.g., disparate naming conventions like Cell_Phone versus Mobile_No).
- Data Source Object (DSO) Abstraction: Standardized incoming schemas at the ingestion layer into semantic Data Source Objects.
- Semantic Mapping to Data Model Objects (DMOs): Mapped the DSOs directly to standard templates within the global Cloud Information Model (CIM). This step enforced strict data normalization, ensuring all multi-source records shared a unified structural taxonomy before entering the identity resolution pipeline.
Phase 3: Deterministic & Probabilistic Identity Resolution Engine
The core of the architecture relies on an advanced Identity Resolution Engine designed to stitch duplicate fragments into a single, cohesive Unified Individual profile.
- Deterministic Exact Match Rules: Configured rigorous normalization rules to strip formatting anomalies from key identifiers (e.g., telephone string formatting variations), enabling reliable deterministic matching.
- Probabilistic Fuzzy Matching: Implemented fuzzy logic to catch typographic errors in name fields while cross-referencing stable secondary identifiers (like matching email addresses) to prevent false negatives.
- Data Reconciliation & Consolidation Policies: Established strict attribute-level selection rules to handle multi-source data conflicts. Configured the engine to prioritize source data based on Most Recent Recency to ensure the unified profile maintains maximum data freshness.
Phase 4: Low-Latency Event Ingestion (Streaming API)
To capture live user engagement and behavioral signals, I supplemented the batch architecture with a real-time event pipeline.
- External Client Apps (ECA) Authentication: Configured a secure External Client App framework within Salesforce to manage OAuth authorization scopes.
- REST Streaming API Integration: Utilized Postman to develop, validate, and test high-frequency streaming payloads, successfully funneling real-time behavioral telemetry straight into Data Cloud for immediate processing.
1. High-Volume Ingestion Layer
2. Schema Harmonization via CIM
Raw incoming source streams are mapped straight into unified Data Source Objects (DSOs)[cite: 1].
Enforces strict structural data normalization to remove multi-source schema friction[cite: 1].
3. Advanced Identity Resolution Engine
Exact match string clearing to resolve formatting deviations across static identifiers[cite: 1].
Fuzzy logic processing to catch typographical spelling anomalies while validating secondary tags[cite: 1].
Resolves record system collisions by explicitly prioritizing data based on Most Recent Recency[cite: 1].
Unified Individual Profile (Single Source of Truth)
A centralized, enterprise-grade 360-degree interactive profile built for sub-second activations[cite: 1].
Architectural Troubleshooting & Resolutions Log
During the implementation, I navigated several enterprise security and integration roadblocks. Below is the technical breakdown of the issues encountered and their structural resolutions:
| Core Issue | Root Cause Analysis | Architectural Resolution |
INVALID_FIELD Exception | Attempted to establish a data model relationship between a Contact and a Manager using a custom plain-text identifier, violating Salesforce’s standard relational schema requirements. | Refactored the data mapping layer to bind the incoming hierarchical reference directly to the standard ReportsTo.Id field, satisfying relational database integrity constraints. |
| Missing “Connected App” Interface | Recent Salesforce platform security hardening deprecates or hides legacy Connected App creation pathways by default. | Pivoted to the modern External Client Apps (ECA) framework. Manually generated the deployment manifests and explicitly defined trusted callback URLs to align with secure OAuth practices. |
Postman invalid_grant Error | Default org security policies restricted standard resource owner password credentials flows via the API to mitigate brute-force vectors. | Transitioned the integration to a robust OAuth 2.0 Client Credentials Flow. Configured the backend execution policies and explicitly assigned API permissions to a dedicated integration user profile. |
Streaming API 404 Not Found & Payload Rejections | Syntax discrepancies in the target endpoint URL string and non-ISO compliant single-quote boundaries in incoming datetime payloads. | Sanitized the URI routing paths to match the exact Streaming API specification. Refactored the payload transformer to generate strictly compliant timestamps, resolving structural parsing issues to achieve a consistent 202 Accepted ingestion status. |
Architectural Conclusions
The successful implementation of the PR 5: Data 360 engine demonstrates that maximizing Salesforce Data Cloud extends far beyond basic administrative configuration. It demands a rigorous approach to cross-system data transformation, an understanding of cloud identity resolution theory, defensive API design, and systemic debugging.
The resulting framework delivers a highly scalable, real-time data layer that empowers an organization with clean, actionable, and completely unified customer intelligence.
Looking to streamline your enterprise workflows, break down data silos, or connect your software ecosystem seamlessly? Explore more technical case studies on Sureshbiztech or get in touch for custom automation architecture solutions.